- トップ >
- データベース(職業能力開発支援情報) >
- 専門課程・応用課程課題情報検索 >
- 課題情報を検索する >
- 課題の要約
XPathを利用した『Webページ上の情報抽出ソフトウェア』の制作(H21)
| 大学校及び設置科 | 中国職業能力開発大学校 情報技術科 |
|---|---|
| 課題実習の前提となる科目または知識、技能・技術 | 工場内ネットワーク、システムプログラム、ソフトウェア設計、コンテンツ制作、Webアプリケーション |
| 課題に取り組む推奨段階 | コンテンツ制作実習およびWebアプリケーション実習終了後 |
| 課題によって養成する知識、技能・技術 | 課題を通して、主にWebクライアント/Webサーバプログラミングおよび連携プログラミング技術の実践力を身に付けます。 |
製作の目的と概要
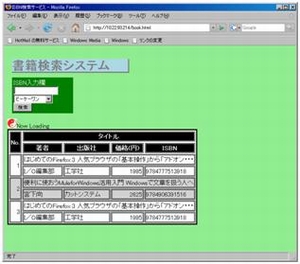
そこで本制作では、書籍のISBNをバーコードリーダーで読み取り、amazon.co.jp(R)などのWebサイトからタイトル・著者などの書籍情報をXPathを利用して取り出し表示する情報抽出ソフトウェアを作成しました。
成果
処理したデータは、メインページに埋め込まれたJavaScriptでAjaxを利用し、非同期で動的に処理し、テーブル形式で次々と表示します。図1は実際に実行した画面です。